Jak działa przeglądarka i po co jest HTML?
 źródło:https://academind.com/tutorials/how-the-web-works
źródło:https://academind.com/tutorials/how-the-web-works
Witam Cię serdecznie na pierwszej lekcji kursu html gdzie przejdziemy od podstaw do poziomu średnio zaawansowanego i w międzyczasie połączymy to z CSS-em i JavaScriptem żeby realizować praktyczne projekty.
W tej lekcji wyjaśnię co dzieje się w przeglądarce po wpisaniu nazwy strony internetowej w pasku wyszukiwania, aż do wyświetlenia pięknej stronki i gdzie w tej całej układance znajduje się język HTML.
Zacznijmy od najbardziej oczywistego sposobu korzystania z Internetu: odwiedzasz witrynę, Taką jak na przykład https://witekpruchnicki.com, do czego oczywiście szczerze zachęcam.
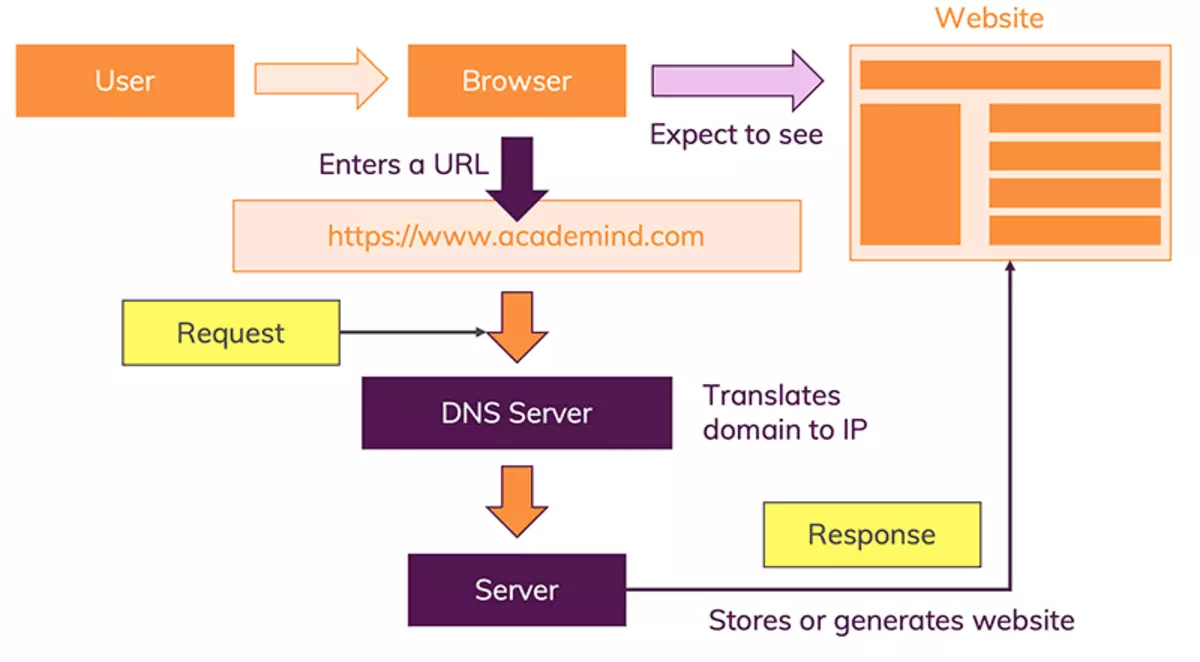
W chwili, gdy wpiszesz ten adres w przeglądarce i naciśniesz ENTER, dzieje się wiele różnych rzeczy:
- Określenie adresu url i rozpoznanie adresu IP
- Wysłanie zapytania do serwera strony internetowej
- Odpowiedź serwera i przesłanie kodu strony
- Strona jest renderowana i następnie wyświetlana
Kod strony internetowej, którą chcesz wyświetlić oczywiście nie jest przechowywany na Twoim komputerze i dlatego musi być on pobrany z innego komputera, na którym jest przechowywany. Ten „inny komputer” jest nazywany „serwerem”.
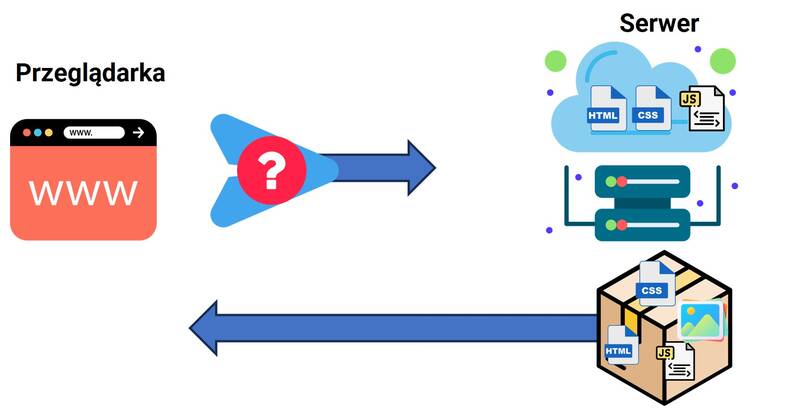
Jest to nic innego jak specjalistyczny komputer, który przechowuje pliki z których składa się strona internetowa i obsługuje przesyłanie tych plików do przeglądarki. Następnie przeglądarka po przeanalizowaniu tych wszystkich plików może wyświetlić zawartość strony internetowej użytkownikowi czyli Tobie.
Po wpisaniu adresu strony internetowej czyli inaczej nazywanego domeną, nazwa ta musi być przekształcona bo serwer, na którym znajduje się kod źródłowy strony internetowej, jest identyfikowany za pomocą adresów IP czyli Protokołu Internetowego. Chodzi o to, że musimy mieć jakiś konkretny adres gdzie znajdziemy dany serwer. To tak jak idziesz do kogoś i chcesz od niego coś otrzymać no to nie ma innej opcji, musisz znać adres żeby otrzymać to na czym Ci zależy.
Adres IP zwykle wygląda tak: 188.210.221.82 (chociaż istnieje również bardziej „nowoczesna” forma o nazwie IPv6 - ale na razie się tym nie zajmujemy)
Domena, którą wpisałeś w pasku wyszukiwania to nic innego tylko ułatwienie dla ludzi, żeby łatwiej było zapamiętać daną nazwę. Czyli teraz żeby przeglądarka mogła wysyłać „żądanie” do serwera o określonym adresie IP, musi dowiedzieć się jaki jest ten adres IP.
Do tego służy specjalny typ serwera czyli serwer DNS z angielskiego „Domain Name System”). Takich serwerów jest wiele i są one rozsiane po całym świecie.

Zadaniem tych serwerów DNS jest tłumaczenie domen na adresy IP. Możesz sobie wyobrazić te serwery jako ogromne książki telefoniczne, które przechowują tabele z 2 kolumnami. Nazwa Domeny i Adres IP. Czyli przykładowo

Teraz jeszcze jedna kwestia domena jest nazwą witryny a adres URL prowadzi do dowolnej strony w tej witrynie. Każdy adres URL zawiera nazwę domeny, a także inne elementy potrzebne do zlokalizowania określonej strony lub fragmentu treści.

Okej, mamy to. Czyli wracamy i jeszcze raz sobie powtórzmy jak wygląda ten proces.
Po wprowadzeniu „witekpruchnicki.com” przeglądarka najpierw pobiera adres IP z takiego serwera DNS. Następnie serwer DNS tłumaczy domenę na adres IP.
Po rozpoznaniu adresu IP przeglądarka kontynuuje i wysyła żądanie do serwera z tym adresem IP.
Żądanie, które bywa nazywane również zapytaniem do serwera to nic innego jak wysłanie przez przeglądarkę konkretnych informacji, czego oczekuje od serwera. Przeglądarka musi uwzględnić takie kwestie jak dokładny adres URL, typ żądania bo na razie pobieramy stronę ale w przyszłości również będziemy chcieli jakieś dane wysłać do serwera, różne metadane itd. Zbiera te informacje do kupy i taki pakiet danych wysyła do serwera.
Dane przesyłane są za pośrednictwem Protokołu „HyperText Transfer Protocol” (znanego jako „HTTP”) – ustandaryzowanego protokołu, który określa, jak ma wyglądać żądanie (i odpowiedź), jakie dane mogą być zawarte (i w jakiej formie) oraz wiele innych informacji.
Nawet jeśli podczas wpisywania nazwy domeny nie wpiszesz na początku protokołu czyli http lub https to przeglądarka automatycznie uzupełni je za Ciebie.
Zatem po wpisaniu nazwy domeny pełny adres URL, będzie wyglądał tak: http://witekpruchnicki.com
Jest też HTTPS, czyli zalecana i bezpieczniejsza wersja protokołu HTTP, która jest szyfrowana a większość nowoczesnych stron używa HTTPS zamiast HTTP.
Obecnie strony bez protokołu HTTPS uznawane są przez przeglądarki za niebezpieczne.
Zatem nawet jak wpiszesz HTTP, to wymuszone zostanie przekierowanie na HTTPS i Pełny adres URL zmieni się wtedy na: https://witekpruchnicki.com.
Następnie serwer odpowiednio obsługuje żądanie i zwraca tak zwaną „odpowiedź”.
Czyli skoro serwer otrzymał zapytanie o konkretne informacje to w odpowiedzi przesyła informacje i kod wymagany do wyświetlenia strony na ekranie.
Podobnie jak żądanie, odpowiedź może zawierać dane, metadane itp. W przypadku żądania strony takiej jak witekpruchnicki.com odpowiedź będzie zawierać kod
Co dzieje się na serwerze, gdy otrzymuje zapytanie od przeglądarki?
To wszystko zależy w jakich technologiach została utworzona strona bo nie ma tutaj jednoznacznej odpowiedzi.
Niektóre serwery są zaprogramowane do dynamicznego generowania stron internetowych na podstawie żądania (np. strona profilu zawierająca Twoje dane osobowe), inne serwery zwracają wstępnie wygenerowane strony HTML (np. strona z wiadomościami). Albo jedno i drugie — dla różnych części strony internetowej.
Istnieje również trzecia alternatywa: strony internetowe, które są wstępnie generowane, ale zmieniają swój wygląd i dane w przeglądarce.
Nie będziemy się tym zajmować bo to już wyższy poziom wtajemniczenia i w tym materiale omawiam jak to wygląda w klasycznej i najprostszej stronie internetowej, która zbudowana jest z kodu HTML, CSS i JavaScript. Zatem w naszym prostym przypadku mamy serwer, który zwraca kod do wyświetlenia strony internetowej.
Kolejny etap obejmuje analizę odpowiedzi wysłanej przez serwer, która nazywana jest parsowaniem. Parsowanie to proces który polega na wzięciu kodu strony zapisanego jako tekst czyli np. pliku HTML, CSS a następnie przetransformowaniu go do czegoś z czym przeglądarka potrafi pracować. Czyli najpierw przeglądarka wysłała zapytanie do serwera, wszystko poszło po naszej myśli i przeglądarka otrzymuje informacje od serwera w formie odpowiedzi.
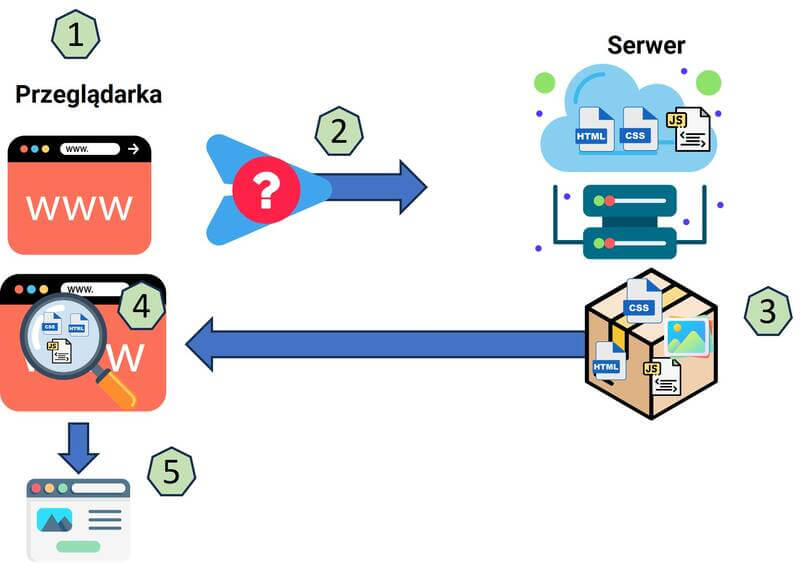
- 1. Wpisanie nazwy domeny - określony zostaje adres URL a następnie adres IP serwera za pomocą DNS
- 2. wysłanie przez przeglądarkę zapytania do serwera
- 3. Przesłanie odpowiedzi od serwera
- 4. Analiza przez przeglądarkę otrzymanych plików i danych
- 5. Wyświetlenie strony użytkownikowi
Żeby cokolwiek pojawiło się na ekranie to ta odpowiedź od serwera musi zostać przez przeglądarkę przeczytana i przeanalizowana.
Przeglądarka sprawdza dane i metadane zawarte w odpowiedzi. I na tej podstawie decyduje, co robić dalej. W przypadku naszej prostej strony internetowej odpowiedź zawierałaby określone metadane, które informują przeglądarkę, że dane odpowiedzi są typu text/html. Ponieważ przeglądarka wysłała Nagłówek Content-Type o treści text/html, ponieważ oczekuje treści HTML.
Dzięki temu przeglądarka może następnie przeanalizować rzeczywiste dane dołączone do odpowiedzi jako kod HTML.
HTML to z angielskiego Hyper Text Markup Language i jest rdzeniem stron internetowych ponieważ opisuje strukturę strony internetowej.
Kod wygląda następująco:
Jeśli chcesz coś pozmieniać i się pobawić to możesz zmieniać bezpośrednio w edytorze i powinno się na bieżąco przeładowywać po prawej stronie. Jeśli to nie zadziała, wówczas w lewym dolnym rogu wybierz opcję Edit on Stackblitz i gdy wprowadzisz swoje zmiany i użyjesz CTR + S to pojawi się komunikat project forked i możesz wówczas pobawić się z HTML-em.
Każdy tag HTML ma jakieś znaczenie semantyczne, które przeglądarka rozumie, ponieważ HTML jest również ustandaryzowany. Dlatego nie ma zgadywania, co oznacza znacznik bo określa on najważniejszy Nagłówek na danej stronie.
Przeglądarka wie, jak analizować kod HTML i teraz, gdy otrzymała odpowiedź od serwera to po prostu przegląda wszystkie dane odpowiedzi (zwane także „treścią odpowiedzi”), aby wyświetlić witrynę.
Ostatni krok to wyświetlenie strony internetowej użytkownikowi.
Przeglądarka przegląda dane HTML zwrócone przez serwer i na ich podstawie buduje stronę internetową.
 źródło:https://www.figma.com/community/file/1053304969390475630/Basic-Structure-of-a-HTML-Page
źródło:https://www.figma.com/community/file/1053304969390475630/Basic-Structure-of-a-HTML-Page
Chociaż ważne jest, aby wiedzieć, że HTML nie zawiera żadnych instrukcji dotyczących tego, jak strona powinna wyglądać (tj. jaki powinien być styl). Tak naprawdę definiuje jedynie strukturę i informuje przeglądarkę, która treść jest nagłówkiem, która treść jest obrazem, która treść jest akapitem itp.
Jest to szczególnie ważne dla urządzeń takich jak czytniki ekranów dla osób z niepełnosprawnościami ponieważ urządzenia te pobierają wszystkie przydatne informacje ze struktury HTML. Zatem napisany kod musi być semantyczny czyli znaczniki w maksymalnym stopniu mają określać treść.
Strona zawierająca tylko HTML wyglądałaby niestety tak:
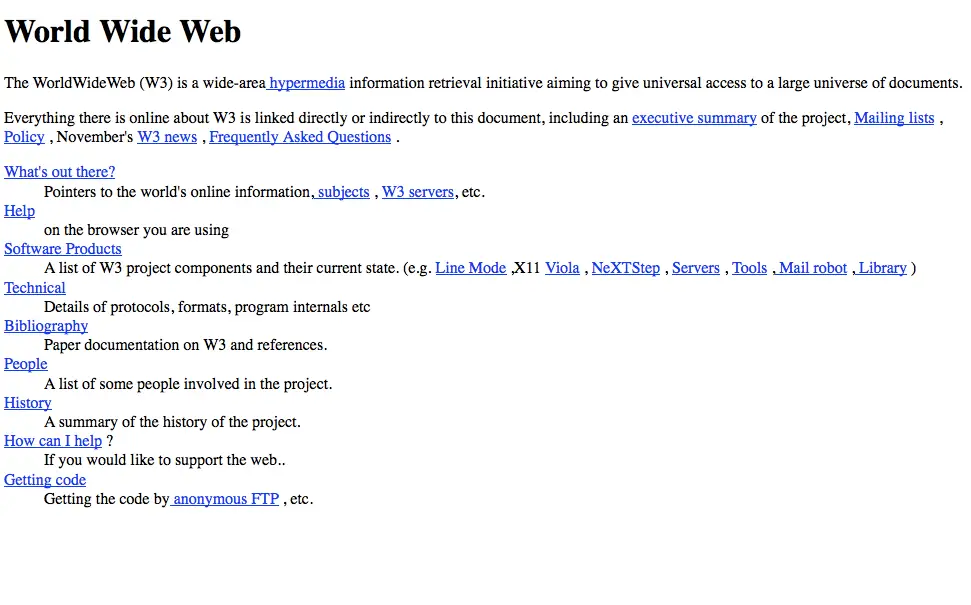
No jak sam widzisz szału nie ma No i można powiedzieć że taka strona jest po prostu brzydka.
Dlatego istnieje inna ważna technologia, która odpowiada za wygląd i warstwę wizualną na stronie czyli CSS, co oznacza „Kaskadowe arkusze stylów”
Zasada działania CSS polega na dodawaniu stylu do strony internetowej. Odbywa się to za pomocą „reguł CSS”:
Czyli przykładowo jeśli chcemy zmienić ten nagłówek, żeby nie wyglądał tak jak teraz czyli domyślnie, tylko chcemy go zmienić na kolor czerwony, to za pomocą reguł CSS najpierw określamy o który znacznik HTML nam chodzi a następnie określamy jak ma wyglądać. Czyli mówimy że znacznik H1 ma mieć kolor czerwony. No i proszę bardzo mamy czerwony Nagłówek h1.
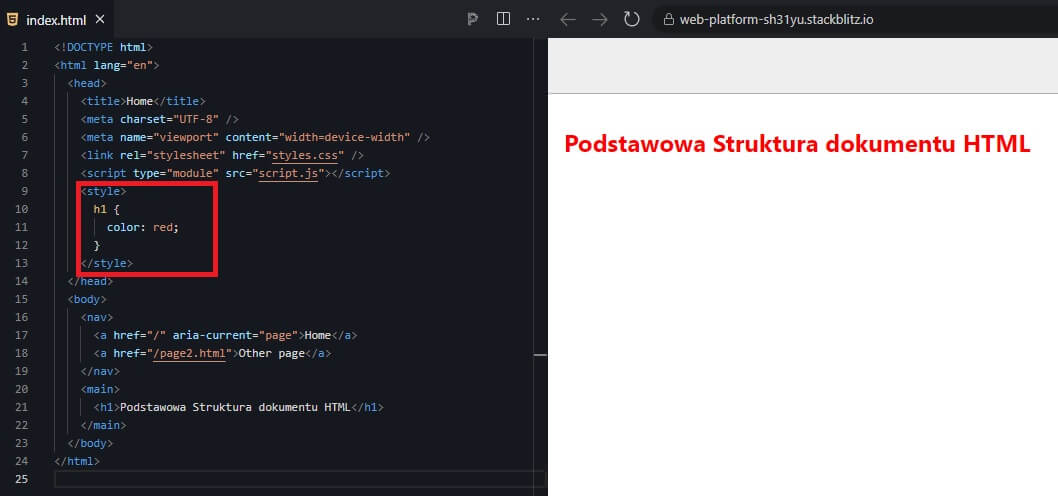
Takie reguły można dodać w kodzie HTML, w tak zwany sposób liniowy, ale polecaną opcją jest rozdzielenie kodu strony internetowej na różne rodzaje zatem kod HTML będzie zapisany w pliku o rozszerzeniu .html, i na początek przyjmijmy, że będzie się nazywał ten plik index.html, drugi plik będzie nazywał się style.css, a trzeci z kodem JavaScript będzie się nazywał main.js.
Plik HTML to kręgosłup storny internetowej zatem do niego załączamy plik CSS i JS, czyli to tak jakbyśmy chcieli wkleić cały kod CSS i JavaScript do strony internetowej. Natomiast żeby tego nie kopiować i utrzymywać porządek w kodzie to rozdzielamy kod storny internetowej na te pliki a przeglądarka poradzi sobie z tym i jak zobaczy, że w kodzie HTML jest załączony plik CSS lub JavaScript to sama rozpocznie analizę tego kodu.
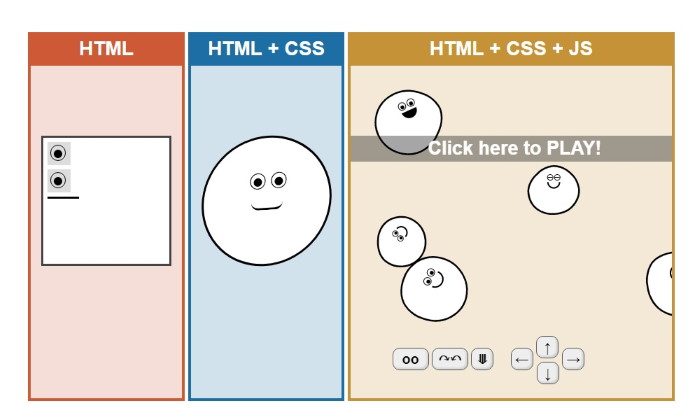 źródło: https://html-css-js.com/
źródło: https://html-css-js.com/
Powtórka, Plik HTML to struktura strony internetowej, CSS to warstwa wizualna i ładny wygląd a JavaScript to wszystko to co jest interaktywne i dynamiczne. Czyli jeśli coś się pojawia zmienia, pokazuje i ogólnie jest na takiej stronie życie to właśnie odpowiada za to JavaScript.

Nie zagłębiając się tutaj w zbyt wiele szczegółów, otrzymany od serwera kod HTML w pierwszej odpowiedzi zawiera po prostu instrukcje pobierania większej ilości danych za pośrednictwem nowych żądań — a przeglądarka rozumie te instrukcje: czyli na przykład
Przeglądarka wysyła wiele żądań do serwera w celu pobrania wszystkich zasobów zewnętrznych. Czyli to nie jest tak że jedno zapytanie i już, no nie tutaj następuje wymiana informacji pomiędzy przeglądarką a serwerem, przeglądarka oczekuje informacji a serwer je przygotowuje i przesyła aby przeglądarka mogła je następnie przeanalizować i wyświetlić użytkownikowi.
Mam nadzieję, że wiesz jak to już działa i w kolejnych materiałach z tej serii przejdziemy do omówienia podstaw i bardziej zaawansowanych zagadnień języka HTML.